Triton Inference Server란
Triton server는 DL의 model을 Inference하는데 GPU의 자원을 최적으로 할당하여 활용도를 극대화 하여 Inference server를 구축하기 편하게 해준다. 그리고 tensorflow, TensorRT, Caffe2, pytorch 등과 같은 주요 framework를 지원하면서 docker container 기반의 Open-source inference serving software이다.
아래 링크는 triton inference server에 대해 자세히 설명되어 있는 nvidia 홈페이지와 Git 주소이다.
https://developer.nvidia.com/nvidia-triton-inference-server
NVIDIA Triton Inference Server
NVIDIA Triton Inference Server NVIDIA Triton™ Inference Server simplifies the deployment of AI models at scale in production. Open-source inference serving software, it lets teams deploy trained AI models from any framework (TensorFlow, NVIDIA® TensorRT
developer.nvidia.com
https://github.com/triton-inference-server/server
GitHub - triton-inference-server/server: The Triton Inference Server provides an optimized cloud and edge inferencing solution.
The Triton Inference Server provides an optimized cloud and edge inferencing solution. - GitHub - triton-inference-server/server: The Triton Inference Server provides an optimized cloud and edge i...
github.com
Triton Inference Server server 실행
Triton Inference Server를 사용하기 위해서 우선 server를 실행해야 한다.
예제 모델은 위의 github 링크에서 프로젝트를 git clone하고, clone된 server폴더 안에서 docs/examples/model_repository에 들어가면 예제로 되어 있는 모델이 들어 있다.

이때, densenet_onnx나 inception_graphdef 등을 보면 폴더 1이 있고 그 안에 모델이 들어있어야 하는데 모델을 얻기 위해서는 'docs/examples'에 있는 'fetch_models.sh'를 실행해 준다.
cd docs/examples
./fetch_models.sh
docker로 server를 실행하기 전에 image를 pull하는데 사용할 tritonserver의 version을 지정해 줘야 한다.
docker pull nvcr.io/nvidia/tritonserver:<xx.yy>-py3
ex) docker pull nvcr.io/nvidia/tritonserver:21.03-py3만약, 자신의 tensorrt 모델을 사용해서 하고 싶은 경우, 사용하고 있는 tensorrt의 version에 맞춰서 tritonserver version을 지정해 줘야 한다.
tensorrt의 버전은 밑의 링크에 보면 알 수 있다.
https://docs.nvidia.com/deeplearning/tensorrt/container-release-notes/rel_21-08.html#rel_21-08
Container Release Notes :: NVIDIA Deep Learning TensorRT Documentation
The NVIDIA container image for TensorRT, release 21.08, is available on NGC. Contents of the TensorRT container This container includes the following: The TensorRT C++ samples and C++ API documentation. The samples can be built by running make in the /work
docs.nvidia.com
tritonserver pull이 완료 되었으면 위의 예제 모델이 있는 path를 포함해서 docker run을 해주면 server는 실행된다.
docker run --gpus=1 --rm -p8000:8000 -p8001:8001 -p8002:8002 -v <model path>:/models nvcr.io/nvidia/tritonserver:<xx.yy>-py3 tritonserver --model-repository=/models
ex) docker run --gpus=1 --rm -p8000:8000 -p8001:8001 -p8002:8002 -v /server/docs/examples/model_repository/:/models nvcr.io/nvidia/tritonserver:21.03-py3 tritonserver --model-repository=/models
server 실행이 완료되면 밑의 그림과 같이 나오게 된다.

triton server 실행이 완료되었으면 client를 실행하면 되는데 이때 docker container 내부에서 할 수도 있고, local에서 실행해도 상관 없다.
Triton Inference Server server 실행 - docker container
client를 docker container에서 작업하고 싶으면 tritonserver sdk image를 pull해야 한다.
docker pull nvcr.io/nvidia/tritonserver:<xx.yy>-py3-sdk
docker run -it --rm --net=host nvcr.io/nvidia/tritonserver:<xx.yy>-py3-sdk
ex) docker pull nvcr.io/nvidia/tritonserver:21.03-py3-sdk
docker run -it --rm --net=host nvcr.io/nvidia/tritonserver:21.03-py3-sdk
예제 model이 잘 돌아가는지 test하고 싶으면 'workspace/install/bin'에 있는 image_client를 사용해서 다음과 같은 명령어를 쳐보면 된다.
/workspace/install/bin/image_client -m densenet_onnx -c 3 -s INCEPTION /workspace/images/mug.jpg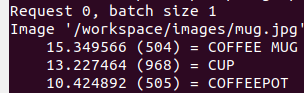
만약 custom model을 load해서 직접 코드를 수정하고 사용하고 싶으면 '/workspace/install/python'에서 image_client.py를 수정하여 사용하면 작업하기 쉽다.
Triton Inference Server server 실행 - local
docker container 내부에서가 아닌 local에서 작업하고 실행하고 싶으면 밑의 링크에서 git clone을 하면 되고, 'src/python/examples'에 있는 코드를 사용하면 된다.
https://github.com/triton-inference-server/client
GitHub - triton-inference-server/client: Triton Python, C++ and Java client libraries, and GRPC-generated client examples for go
Triton Python, C++ and Java client libraries, and GRPC-generated client examples for go, java and scala. - GitHub - triton-inference-server/client: Triton Python, C++ and Java client libraries, and...
github.com




댓글