본 논문은 2020 CVPR에 발표된 논문으로 모델을 pruning 하는 방법들 중에서 filter prunning방법으로 모델을 경량화하는 방법을 사용한다.
Paper: https://arxiv.org/pdf/1904.12368.pdf
Github: https://github.com/cmu-enyac/LeGR
GitHub - cmu-enyac/LeGR: CNN channel pruning, LeGR, MorphNet, AMC. Codebase for paper "LeGR: Filter Pruning via Learned Global R
CNN channel pruning, LeGR, MorphNet, AMC. Codebase for paper "LeGR: Filter Pruning via Learned Global Ranking" - GitHub - cmu-enyac/LeGR: CNN channel pruning, LeGR, MorphNet, AMC. Codebas...
github.com
Abstract
본 논문에서는 미리 정의된 latency constraint를 대상으로 한 ConvNet을 생성하는 대신, 다양한 accuracy와 latency의 trade-off를 통해 ConvNet의 set을 생성하도록 model compression의 목표를 변경하여 이 프로세스를 보다 효율적으로 만들기 위해 수행한다. 이를 위해 bottom-ranked filter를 pruning 함으로써 accuracy / latency의 trade-off가 서로 다른 ConvNet 아키텍처 집합을 얻는 데 사용되는 filters의 global ranking을 ConvNet의 여러 계층에 걸쳐 학습할 것을 제안한다.
1. Introduction
Filter pruning의 핵심 아이디어는 accuracy degradation을 최소화하고, speed improvement를 최대화여 제거할 가장 중요하지 않은 filter를 찾는 것이다. state-of-the-art인 filter pruning method는 pruned network를 얻기 위해 전체 ConvNet의 target model complexity(예를 들어, 전체 filter의 수, FLOP 수, 모델 크기 등)를 필요로 하지만, embeded AI application의 최적화를 위한 target model complexity를 결정하는 것은 어려울 수 있다. 다시 말하면 사용자의 환경이 accuracy와 speed에 영향을 미칠 수 있어 이러한 경우 ConvNet의 speed와 accuracy 사이의 최적의 trade-off point를 찾기 위해 시행착오 방식(trial-and-error fashion)을 여러 번 반복해야 하고, 시간이 많이 걸릴 수 있다.
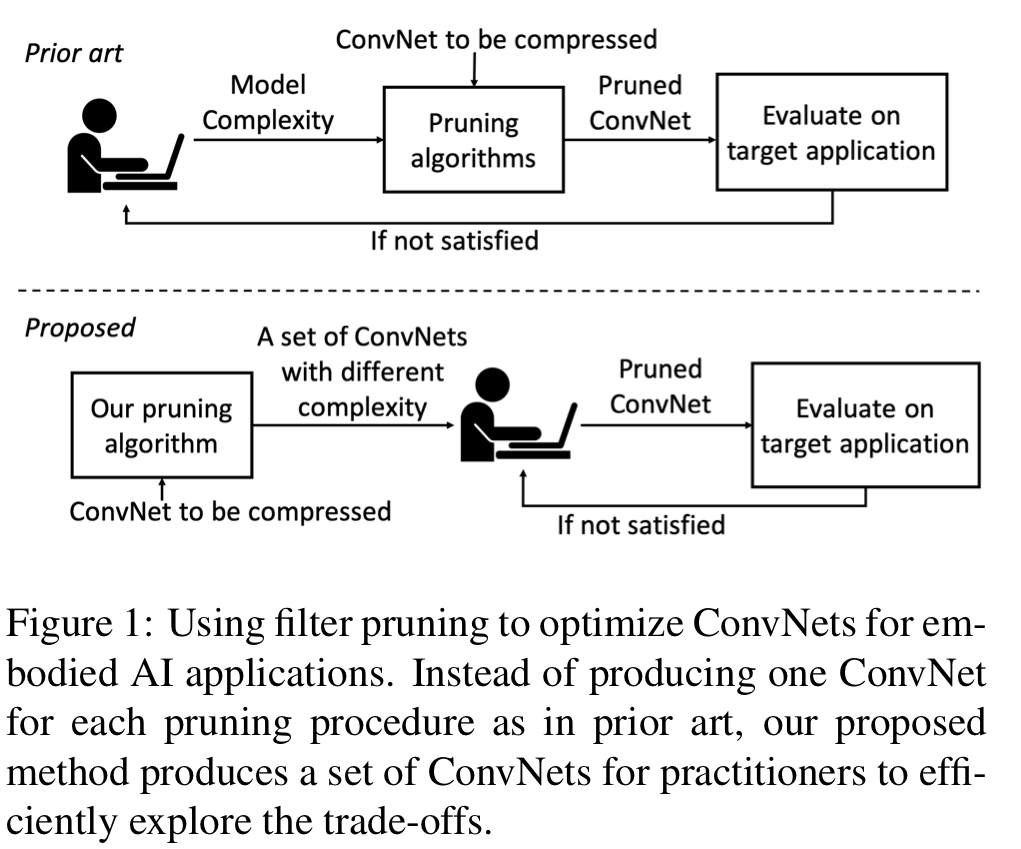
그림 1은 이전에 사용되어 오던 filter pruning 방식과 본 논문에서 제안하는 filter pruning 방식을 보여준다. 이전에 사용하던 방식은 accuracy와 speed의 균형을 만족할 때까지 고려되는 모든 model complexity에 대한 pruning algorithm을 통해 constraint를 충족하는 pruned-ConvNet을 찾는 프로세스를 거쳐햐 했다. 본 논문에서는 model complexity로 단일 ConvNet을 출력하는 이전에 사용되어 오던 filter pruning 방식에서 accuracy / speed의 trade-off를 달리하는 ConvNet의 set을 생산하면서 state-of-the-art의 방법을 사용하여 비교할 수 있는 accuracy를 달성한다. 이러한 방식으로 model compression overhead를 크게 줄일 수 있으므로 필터 가지치기를 보다 실용적으로 사용할 수 있다. 이를 위해 본 논문에서는 bottom-ranked filter를 제거하여 speed/accuracy trade-off의 ConvNet architecture를 쉽게 얻을 수 있도록 여러 계층에 걸쳐 convolutional filter의 rank를 정하는 알고리즘인 Learned Global Ranking(LeGR)을 제안한다.
3. Learned Global Ranking
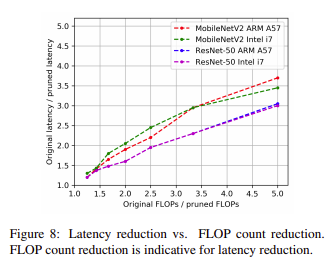
본 논문에서의 핵심 아이디어는 주어진 complexity의 ConvNet을 bottom-rank filter를 제거하여 쉽게 얻을 수 있도록 서로 다른 layers에 걸쳐 filter의 rank를 학습하는 것으로 model complexity에 FLOP count를 사용하여 ConvNet을 sampling한다. 그림 8은 FLOP count가 감소하면 latency도 줄어드는 것을 보여주고 있다.
3.1 Global Ranking
본 논문에서는 두 가지 Assumption을 제시하면서 주어진 ConvNet에 대한 global ranking을 한번만 학습하고, FLOP count가 다른 pruned-ConvNet을 얻기 위해 layers에서 filter ranking을 전체적으로 학습할 것을 제안한다.
- global ranking formulation에서는 top-performing smaller ConvNets가 top-performing larger ConvNets의 적절한 하위 집합이라는 가정을 적용한다.
위의 가정을 통해 FLOP count가 서로 다른 pruned-ConvNets를 생성할 수 있는 global filter ranking을 지정할 수 있다. 위의 가정을 좀 더 공식적으로 명시하면 다음과 같다.

- filter norm이 filter의 rank를 로컬(intra-layer-wise)로 지정할 수 있지만 전역(inter-layer-wise)으로 지정할 수는 없다고 가정한다.

본 논문에서 인용한 [32, 62, 20]을 보면 filter norm이 채택되고 검증되어 있음을 알 수 있어, 여러 layer에서 filter norm을 비교하기 위해 layer-wise affine transformations를 학습할 것을 제안한다.

위의 식은 i번째 필터의 중요도를 나타낸 식이다. 여기서 l(i)는 i번째 filter에 대한 layer index이고, ||·||2는 l2 norm, θi는 i번째 filter에 대한 weight를 나타내며, α ∈ RL, κ ∈ RL은 layer별 scale 및 shift value을 나타내는 학습 가능한 parameter이며, L은 layer의 수를 나타낸다. Eq. (1) (즉, α-k 쌍)에서 학습된 affine transformation을 바탕으로, LeGR 기반의 pruning은 그림 2와 같이 관심 FLOP count가 충족되도록 I(i번째 필터의 중요도) 및 bottom-ranked filter를 사용하여 전 전역으로 filter의 rank를 매김으로써 I(i번째 필터의 중요도)에서 더 작은 filter를 제거한다.

3.2 Learning Global Ranking
α와 k를 학습하기 위해, α와 k로 rank를 구성하고 다른 FLOP count에 걸쳐 ConvNets를 균일하게 sampling하여 rank를 평가하는 것을 고려할 수 있지만, 서로 다른 FLOP count로 얻은 ConvNets는 validation accuracy가 크게 다르며, 다른 FLOP 카운트로 얻은 ConvNet 전체의 validation accuracy를 normalize 하려면 pruning의 Pareto curve를 알아야 한다.
Pareto curve: 관련있는 두 metrix 사이의 최적의 trade-off 곡선을 설명한다. 본 논문에서의 두 metrix는 정확도와 FLOP
count를 얘기한다.
본 논문에서는 이러한 어려움을 해결하기 위해 α-k 쌍에 의해 유도된 랭킹의 목표로 가장 낮은 고려 FLOP 수에서 얻은 ConvNet의 검증 정확도를 평가할 것을 제안한다. 구체적으로 α와 k를 배우기 위해 LeGR을 최적화 문제(optimization problem)로 취급한다.

식 3의 LeGR-Pruning은 위의 그림 2와 같이 원하는 FLOP count가 충족될 때까지 최하위 필터를 제거한다. Δl(식 3 LeGR-Pruning의 3번째 인자)은 고려된 가장 작은 FLOP count를 나타내고, α-k 쌍을 학습하기 위해 하이퍼 hyper-parameter를 최적화하는최적화 알고리즘 중 neural architecture search space에서의 효과를 위해 regularize 된 evalutionary algorithm(EA)을 사용한다.
알고리즘 1의 의사 코드는 evalutionary algorithm(EA)에 대해 설명되어 있다.

좀 더 구체적으로 말하면, 먼저 candidate 집단(a와 k 값)을 생성하고 각 candidate에 대한 fitness를 기록한 후 다음 단계를 반복합니다.
(i) candidate에서 부분 집합을 추출한다.
(ii) 가장 적합한 candidate를 식별한다.
(iii) 가장 적합한 candidate를 mutate하여 새로운 candidate를 생성하고 그에 따라 fitness를 측정한다.
적합한 후보를 mutate하기 위해, layer의 하위 집합을 무작위로 선택하고 현재 값에서 한 단계의 random-walk(예: αl , κl ∀ l ∈ Layer)을 수행한다.
(iv) candidate 집단에서 가장 오래된 candidate를 생성된 후보자로 대체한다.
4. Experiments


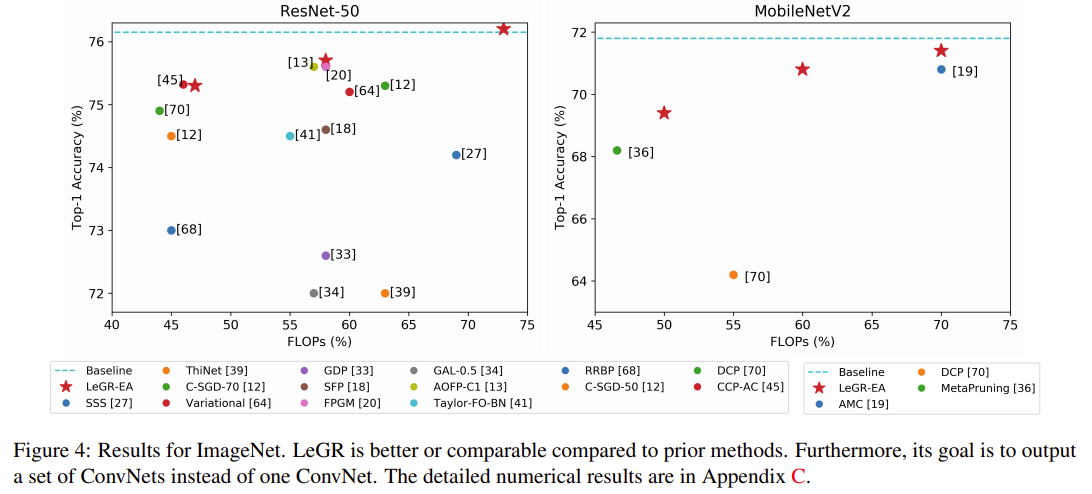
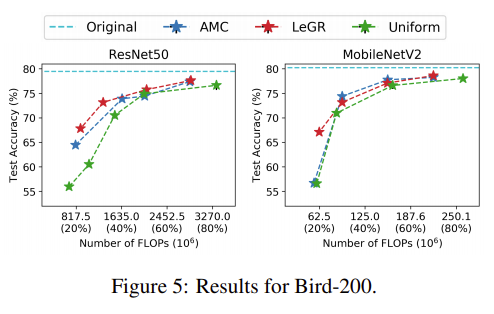
'Development > etc' 카테고리의 다른 글
| [Keras] keras h5모델 Load와 Inference (0) | 2021.11.23 |
|---|---|
| [Ubuntu18.04] Ubuntu18.04 설치시 nomodeset 설정 (0) | 2021.10.01 |
| [Code Compare]Ubuntu에서 beyond compare, meld 설치 (0) | 2021.09.27 |
| [Face Detection]Sample and Computation Redistribution for Efficient Face Detection (0) | 2021.08.31 |
| [GitHub Desktop] GitHub Desktop Ubuntu 설치 (0) | 2021.08.13 |




댓글